

Introduction
Since early 2026, leading U.S. AI labs have frequently spoken out against so-called “adversarial distillation,” accusing China of using this widely accepted industry technique for “intellectual property theft” and even posing a “national security threat.” Since April, actions from both the U.S. government and the private sector regarding the distillation issue have escalated: the White House Office of Science and Technology Policy (OSTP) released a policy memorandum aimed at curbing distillation; both the Senate and the House are advancing related legislation; and companies such as OpenAI, Anthropic, and Google have established an industry coordination mechanism to counter unauthorized distillation through the Frontier Model Forum. What began as a technical dispute has now moved into the policy arena, becoming a focus of coordinated action across the U.S. government and industry. The shift reveals deeper U.S. unease over China’s AI advances, especially its open-source models, and is likely to further shape the global dynamics of AI innovation and competition.
01 In the Name of Distillation: The Coordination and Escalation of a New Round of Technology Controls
On April 23, 2026, Michael Kratsios, Director of the White House Office of Science and Technology Policy, released NSTM-4, a memorandum titled Adversarial Distillation of American AI Models (hereafter, the memo). The memo states that foreign entities, specifically based in China, are distilling frontier U.S. AI systems on a “deliberate, industrial-scale” through proxy accounts and evasion techniques to engage in what it describes as attempts to “systematically extract capabilities from American AI models.” In this regard, the memorandum requires the private sector and the government to strengthen information-sharing mechanisms, collaborate on synthesizing response experiences and mitigation protocols, and assist enterprises in coordinated defense against distillation to avoid fragmented efforts. It also proposes exploring a range of measures to hold foreign actors involved in industrial-scale distillation campaigns accountable.
Furthermore, the memo acknowledges that “legitimate” distillation is an essential component of the AI ecosystem and adopts a softer stance toward open-source community. Yet this openness is carefully qualified: Kratsios emphasized that the United States would continue to “support American industry in making frontier AI broadly accessible to users worldwide” and to safeguard “the free and fair market competition” that enables the “broad and beneficial diffusion of these technologies.” In other words, the goal is not simply to promote global access to frontier AI, but to keep that access and the surrounding competitive order aligned with America’s own interests.

Michael Kratsios attending a hearing.
Source: Associated Press.
This memo responds to the intensifying controversy over distillation within the U.S. AI industry since the beginning of the year. On February 23, 2026, Anthropic issued an official announcement accusing three Chinese AI labs of using a massive number of fraudulent accounts to generate over 16 million exchanges with Claude in order to “illicitly extract Claude’s capabilities” and optimize their own models. Anthropic characterized the conduct as “distillation attacks” and elevated the matter to the level of national security, claiming such actions pose “significant national security risks” to the United States. Furthermore, the announcement also emphasized the strategic necessity and justification for U.S. export control policies on AI chips to China. OpenAI echoed a similar line, warning against attempts to advance AI capabilities by “appropriating and repackaging American innovation.”
Despite the well-known tensions between the CEOs of Anthropic and Open AI, the two companies have actively sought cooperation in response to the so-called “adversarial distillation” risk. In early April, Bloomberg, citing sources familiar with the matter, reported that the rival AI giants, OpenAI, Anthropic, and Google had begun sharing information through the Frontier Model Forum to join forces in curbing Chinese competitors. The Frontier Model Forum, a non-profit industry organization co-founded by these three companies and Microsoft in 2023, was originally aimed at advancing safety research and best practices for frontier models. It has since become a channel for coordinated efforts to detect “adversarial distillation” attempts, a role that was not part of its publicly stated agenda. Bloomberg reported the cooperation as a “rare collaboration,” saying it underscored the severity of U.S. AI companies’ concerns over the issue.

On February 23, Anthropic published an announcement on its official website accusing three Chinese AI labs, including DeepSeek, of “adversarial distillation.”
Source: Anthropic Official Website.
Recent policy moves suggest that the United States has leveraged distillation as a priority issue to drive internal consolidation and agenda alignment, enabling multi-track coordination and a unified pace across legislative and executive branches. In the memo, Kratsios specifically noted that these initiatives are consistent with the AI Action Plan released by the Trump administration in July 2025, which called for the establishment of an Information Sharing and Analysis Center (ISAC), partly to curb “adversarial data distillation.” Furthermore, the memo came as both the U.S. Senate and the House of Representatives were pursuing a series of measures to regulate AI technologies. On April 22, the day before the memo was issued, the U.S. House Foreign Affairs Committee advanced a package of export control bills, including the Multilateral Alignment of Technology Controls on Hardware Act (MATCH Act, H.R. 8170), the Stop Stealing Our Chips Act (H.R. 6322), and the Deterring American AI Model Theft Act (H.R. 8283). While these bills have different focuses, they collectively tighten controls over the spread of model and algorithmic capabilities, and all passed the committee by wide margins. The agenda of “limiting China’s access to the most critical machines and parts needed to make advanced chips” and preventing the extraction of key technical features from “closed-source, American-owned artificial intelligence models” has drawn broad bipartisan support and created a basis for cooperation. On the same day, the U.S. Senate Judiciary Committee held a hearing titled “Stealth Stealing: China’s Ongoing Theft of U.S. Innovation,” extending the previous narrative of “theft of American intellectual property” into the distillation issue, signaling that subsequent export controls and sanctions will be targeted more directly at models and algorithms.
Additionally, the distillation debate has allowed the United States to extend its domestic policy agenda into diplomatic action abroad. Reuters exclusively reported that, according to a diplomatic cable it reviewed, the U.S. State Department had ordered a global push to draw attention to what it described as “widespread efforts by Chinese companies… to steal intellectual property from U.S. artificial intelligence labs.” The cable, sent to U.S. diplomatic and consular posts around the world, instructed diplomatic staff to raise concerns with foreign counterparts, naming leading Chinese AI companies such as DeepSeek, Moonshot AI, and MiniMax. By this point, the debate over distillation has reached a boiling point, becoming a focal issue across multiple tracks of U.S. policymaking. No longer treated as a neutral technical practice, distillation is increasingly framed in policy discourse through the lenses of “intellectual property theft” and “security risks,” marked with prominent labels of politicization and pan-securitization.
02 The Reality of Distillation: Technical Perspectives Behind the Controversy
Distillation is, at its core, a foundational technology in AI model optimization. It was initially defined as a “teacher-student” training paradigm in which larger models serve as teachers for smaller, more cost-effective, and efficient models, enabling the latter to approximate the former’s performance while significantly reducing computational requirements. Formally introduced by Geoffrey Hinton and others in 2015, the technique has since become a recognized pathway for AI research and development across academia and industry. Scholar Nathan Lambert argues that what is commonly called distillation in the current context of large language models is better understood as “synthetic data.” In industry usage, the term increasingly refers to the practice of utilizing synthetic data generated by leading models as raw material to optimize or iteratively improve other models.
In the very announcement where Anthropic accused others of “distillation attacks,” it also acknowledged that distillation is a “widely used and legitimate training method.” In fact, in today’s AI industry, leveraging the outputs of more capable models as alignment data to train or improve one’s own models is an established practice, not one unique to Chinese companies. Similar precedents can also be found in the Western AI research community: Stanford’s Alpaca and UC Berkeley’s Vicuna, for example, were both developed through distilling from, or fine-tuning on, data generated by, or derived from interactions with GPT-family models. However, when Chinese AI companies follow this same path, they are labeled with “theft,” a charge that inevitably raises questions of double standards—especially since Chinese models are also being distilled by American companies. In March this year, Composer 2, a new model launched by Cursor, the coding tool owned by U.S. AI company Anysphere, was initially promoted as “frontier-level at coding”, accompanied by a technical report on “how we trained it.” It was not until developers discovered the internal model ID “kimi-k2p5-rl” in API responses that the company’s co-founder Aman Sanger admitted Composer 2 was built on Moonshot AI’s open-source Kimi K2.5 as its base. Cursor’s Lee Robinson later clarified that only about a quarter of Composer 2’s compute came from the base model, with the rest coming from Cursor’s own training. Following the exposure of these facts, Elon Musk also commented on X, “Yeah, it’s Kimi 2.5.”
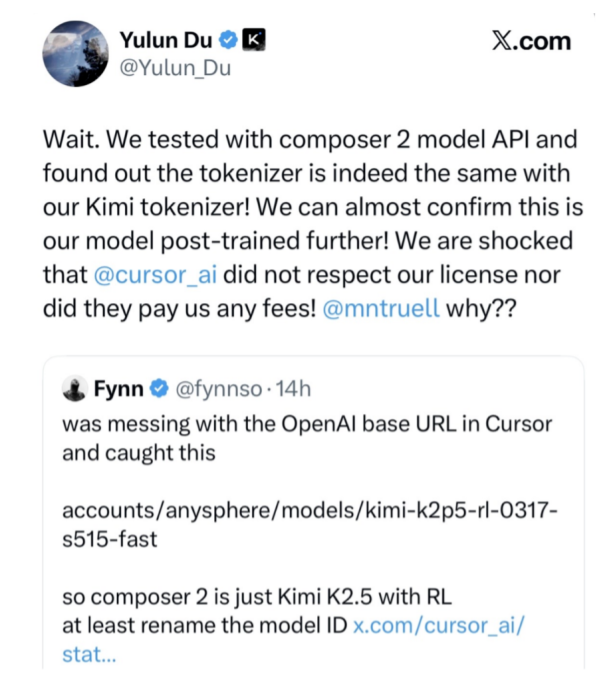
The fact that Composer 2 was based on a fine-tuned version of Kimi K2.5 has spread widely across social media.
Source: X.
Previously, the controversy over distillation had remained largely a dispute among model developers. While there is still no clear legal precedent on whether distilling data from competitors constitutes intellectual property infringement, courts have already addressed related disputes over AI training conducted without authorization from human creators. Anthropic itself serves as an example: between 2024 and 2025, it faced a class-action lawsuit from several authors for allegedly downloading approximately 7 million pirated books from “shadow libraries” to train its models. In June 2025, a California court ruled that training on lawfully acquired books might fall under “fair use,” but allowed claims concerning Anthropic’s acquisition and storage of pirated books to proceed. In September 2025, Anthropic agreed to a proposed $1.5 billion settlement, widely described as the largest known U.S. copyright settlement. Consequently, after Anthropic issued its notice this February, it was ridiculed by Elon Musk: “How dare they steal the stuff Anthropic stole from human coders??”
Now, a consensus has been reached within the U.S. industry and government to explicitly define distillation as “theft”. This is driven, on one hand, by leading U.S. AI companies’ anxiety over the erosion of their competitive moat. Currently, the investment for a single training session of a frontier large model in the U.S. AI industry has reached billions or even tens of billions of dollars. Under such massive cost pressure, if a competitor can acquire similar capabilities at a very low cost through distillation, the initial giant investment shifts from a capital advantage to a disadvantage that lowers the rate of return; hence, companies are seeking government intervention to protect the existing interest structure. On the other hand, it reflects the U.S. government’s strategy of using ambiguity to politicize technical issues. The memo adopts a broad framing of distillation, viewing the use of output data from U.S. models to train one’s own models as a form of copying that effectively “steals” their proprietary mechanisms, training data, and model capabilities. Consequently, critics have argued that by describing learning from outputs as “extracting and copying the innovations of American industry,” the memo has oversimplified the technical process and amplified its policy significance.
03 Beyond Distillation: Misreadings and the Expanding Reach of the Controversy
Looking beyond the surface of the controversy, both the U.S. AI industry and policymakers continue to seize on distillation to maintain and promote a specific narrative: that the rapid development of Chinese AI models is based on American achievements rather than homegrown innovation, and that the United States retains an irreplaceable lead in global AI competition. However, these claims do not hold up under technical and factual scrutiny.
First, while distillation can indeed serve as a shortcut for model training, it cannot replace the independent, deeper-level innovation that drives model capability improvements. Currently, frontier model training increasingly relies on reinforcement learning, real-time environmental feedback, and policy optimization. While distillation might allow a model to approximate the performance of a teacher model on specific tasks, core capabilities such as deep network architecture and inference efficiency optimization cannot simply be transferred wholesale through distillation. These are precisely the areas where a large number of innovative achievements from Chinese open-source models have emerged: DeepSeek’s Multi-head Latent Attention (MLA), DeepSeek Sparse Attention (DSA), and Mixture of Experts (MoE) architecture, as well as Qwen’s base structure. These models have shown strong performance in long-context processing, inference-cost reduction, and knowledge-intensive tasks, putting them on par with Silicon Valley’s top closed-source models. Their breakthroughs stem from high-quality domestic training data and algorithmic iterations. Therefore, the distillation narrative simplifies the overall progress of Chinese large models into mere distillation or even “copying,” seriously underestimating the innovative strength achieved by the Chinese AI industry in open-source collaboration, engineering innovation, and data governance, while overestimating the actual role that distilling U.S. frontier models plays in AI technology diffusion.
Second, China’s homegrown open-source large models are gaining impressive market traction. In early April, official data from OpenRouter, the world’s largest AI model API aggregator, showed DeepSeek-R1 at the top of the “World’s Most Popular Models” list, with Qwen3.6 Plus and DeepSeek V3.2 becoming the most and fourth-most watched open-source models respectively. Among them, the number of Qwen derivative models has exceeded 113,000, far surpassing the 27,000 of Meta’s Llama series, ranking first globally in open-source contribution. This pattern became even more distinct after the release of the DeepSeek V4 preview on April 24, 2026; V4-Pro, with 1.6 trillion parameters, has become the world’s largest open-weight model, with an API output price of only $3.48 per million tokens—significantly lower than similar frontier products from OpenAI, Anthropic, and Google. Notably, the V4 preview was released on the same day as OpenAI’s GPT-5.5 model and just one day after the White House memo was signed. This strategic timing provides a vivid illustration of the current global AI innovation and competition landscape: a real ecosystem formed by global developers’ actual choices serves as a powerful counterweight to the stigmatized and politicized narrative around distillation.
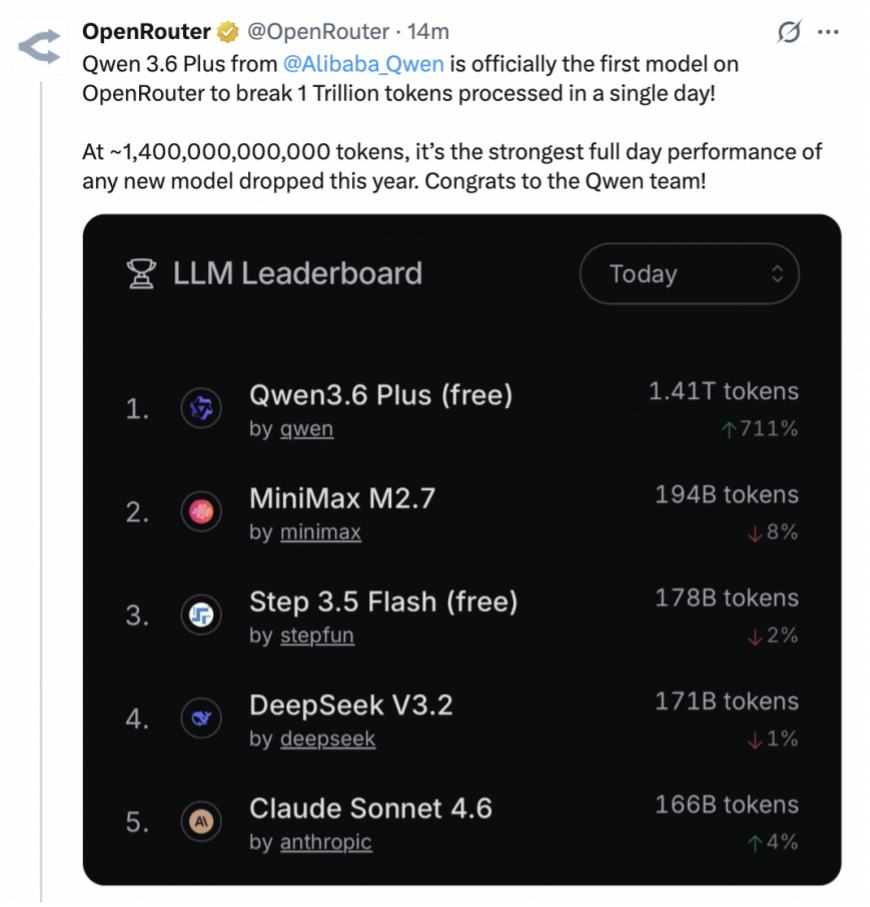
OpenRouter stated on social media that Qwen 3.6 Plus has broken records, calling it the “strongest full day performance of any new model dropped this year.”
Source: X.
The rapid escalation of the distillation controversy reflects a deeper shift in global AI competition where security concerns are increasingly being instrumentalized and rules are being used to constrain rivals. This controversy is thought-provoking not only because of the technical risks themselves but also regarding how to prevent security issues from being abused as bargaining chips to exclude competition. The short-term impact of the U.S. regulatory measures against distillation may lead to a sudden rise in alignment costs during the late stages of training and a gap in the supply of high-quality synthetic data. Over the longer term, however, it may accelerate an industry reshuffle, forcing major large model developers to speed up underlying innovation and pushing the global AI industrial landscape toward multipolarity. Meanwhile, Global South countries, including China, are striving to build more self-reliant AI ecosystems covering computing power, data, and models, using the certainty of technical autonomy to address the uncertainties of the external environment. The healthy development of global AI should not be limited by unilaterally defined “security red lines,” nor should it become the private property of a few technological leaders to maintain their dominance. Advocating for and constructing a new order of AI innovation and governance that transcends geopolitical bias and returns to technological inclusivity requires the joint participation of the international community. Through more concrete technical contributions, more robust institutional designs, and more credible multilateral participation, we can truly bridge the intelligent divide and achieve the inclusive development of AI through openness and sharing.
Original URL: https://mp.weixin.qq.com/s/cQVFzdHRMNxrD16MZlsKcA?scene=1

